
This set of MCQ(multiple choice questions) focuses on the Introduction to Machine Learning NPTEL Week 4 Solutions NPTEL 2023.
With the increased availability of data from varied sources there has been increasing attention paid to the various data driven disciplines such as analytics and machine learning. In this course we intend to introduce some of the basic concepts of machine learning from a mathematically well motivated perspective. We will cover the different learning paradigms and some of the more popular algorithms and architectures used in each of these paradigms.
Course layout
Answers COMING SOON! Kindly Wait!
Week 1: Assignment answers
Week 2: Assignment answers
Week 3: Assignment answers
Week 4: Assignment answers
Week 5: Assignment answers
Week 6: Assignment answers
Week 7: Assignment answers
Week 8: Assignment answers
Week 9: Assignment answers
Week 10: Assignment answers
Week 11: Assignment answers
Week 12: Assignment answers
NOTE: You can check your answer immediately by clicking show answer button. Introduction to Machine Learning NPTEL Week 4 Solutions Assignment Solution” contains 7 questions.
Now, start attempting the quiz.
Introduction to Machine learning NPTEL 2023 Week 4 Solutions
Questions 1-4 with the data provided below:
A spam filtering system has a probability of 0.95 to classify correctly a mail as spam and 0.10 probability of giving false positives. It is estimated that 0.5% of the mails are actual spam mails.
Q1. Suppose that the system is now given a new mail to be classified as spam/not-spam, what is the probability that the mail will be classified as spam?
a) 0.89575
b) 0.10425
c) 0.00475
d) 0.09950
Answer: b) 0.10425
Q2. Find the probability that, given a mail classified as spam by the system, the mail actually being spam.
a) 0.04556
b) 0.95444
c) 0.00475
d) 0.99525
Answer: a) 0.04556
Q3. Given that a mail is classified as not spam, the probability of the mail actually being not spam.
a) 0.10425
b) 0.89575
c) 0.003
d) 0.997
Answer: d) 0.997
Q4. Find the probability that the mail is misclassified:
a) 0.90025
b) 0.09975
c) 0.8955
d) 0.1045
Answer: b) 0.09975
Q5. What is the naive assumption in a Naive Bayes Classifier?
a) All the classes are independent of each other
b) All the features of a class are independent of each other
c) The most probable feature for a class is the most important feature to be considered for classification
d) All the features of a class are conditionally dependent on each other
Answer: b) All the features of a class are independent of each other
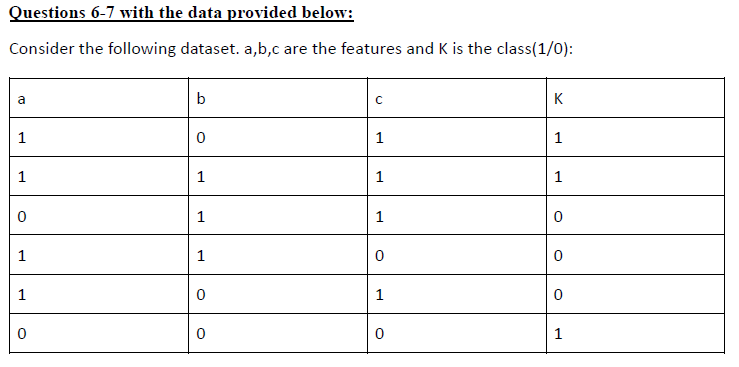
Q6.

Answer: b) 1
Q7. Find P (K=0 | a=1, b=1)
a) 1/3
b) 2/3
c) 1/9
d) 8/9
Answer: b) 2/3
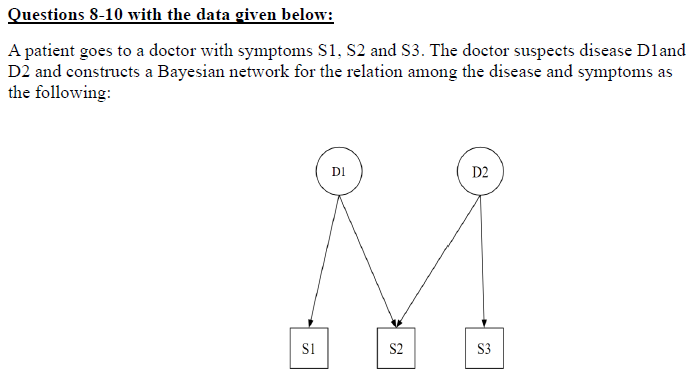
Q8.

Answer: d)
Q9. Suppose P(D1) = 0.4, P(D2) = 0.7, P(S1|D1) = 0.3 and P(S1|D1`) = 0.6. Find P(S1).
a) 0.12
b) 0.48
c) 0.36
d) 0.60
Answer: b) 0.48
Q10. What is the Markov blanket of variable, S3
a) D1
b) D2
c) D1 and D2
d) None
Answer: b) D2
Q11.
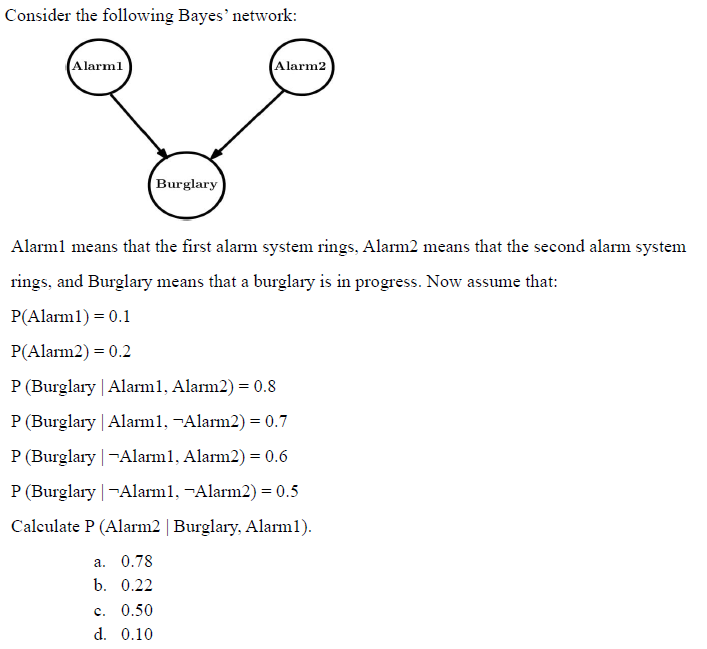
Answer: b) 0.22
Q12.

Answer: b) 0.32
Questions 13-14 with the data given below:
In an oral exam you have to solve exactly one problem, which might be one of three types, A, B, or C, which will come up with probabilities 30%, 20%, and 50%, respectively. During your preparation you have solved 9 out 10 problems of type A, 2 of 10 problems of type B, and 6 of 10 problems of type C.
Q13. What is the probability that you will solve the problem of the exam?
a) 0.61
b) 0.39
c) 0.50
d) 0.20
Answer: a) 0.61
Q14. Given you have solved the problem, what is the probability that it was of type A?
a) 0.35
b) 0.50
c) 0.56
d) 0.44
Answer: d) 0.44
Q15. Naive Bayes is a popular classification algorithm in machine learning. Which of the following statements is/are true about Naive Bayes?
a) Naive Bayes assumes that all features are independent of each other, given the class.
b) It is particularly well-suited for text classification tasks, like spam detection.
c) Naive Bayes can handle missing values in the dataset without any special treatment.
d) It is a complex algorithm that requires a large amount of training data.
Answer: a), b)
Introduction to Machine learning NPTEL 2023 Week 4 Solutions
Q1. Consider a Boolean function in three variables, that returns True if two or more variables out of three are True, and False otherwise. Can this function be implemented using the perceptron algorithm?
a. no
b. yes
Answer: b
Q2. For a support vector machine model, let xi be an input instance with label yi . If yi(β^0+xTiβ^)>1(β^0+β^)>1, where β0β0 and β^)β^) are the estimated parameters of the model, then
a. xi is not a support vector
b. xi is a support vector
c. xi is either an outlier or a support vector
d. Depending upon other data points, x i may or may not be a support vector.
Answer: a
Q3. CSuppose we use a linear kernel SVM to build a classifier for a 2-class problem where the training data points are linearly separable. In general, will the classifier trained in this manner be always the same as the classifier trained using the perceptron training algorithm on the same training data?
a. yes
b. no
Answer: b
Q4. Train a linear regression model (without regularization) on the above dataset. Report the coefficients of the best fit model. Report the coefficients in the following format: β0,β1,β2,β3β0,β1,β2,β3 . (You can round-off the accuracy value to the nearest 2-decimal point number.)
a. -1.2, 2.1, 2.2, 1
b. 1, 1.2, 2.1, 2.2
c. -1, 1.2, 2.1, 2.2
d. 1, -1.2, 2.1, 2.2
e. 1, 1.2, -2.1, -2.2
Answer: d
Q5. Train an l2 regularized linear regression model on the above dataset. Vary the regularization parameter from 1 to 10. As you increase the regularization parameter, absolute value of the coefficients (excluding the intercept) of the model:
a. increase
b. first increase then decrease
c. decrease
d. first decrease then increase
Answer: c
Q6. Train an l22 regularized logistic regression classifier on the modified iris dataset. We recommend using sklearn. Use only the first two features for your model. We encourage you to explore the impact of varying different hyperparameters of the model. Kindly note that the C parameter mentioned below is the inverse of the regularization parameter λλ. As part of the assignment train a model with the following hyperparameters:
Model: logistic regression with one-vs-rest classifier, C=1e4=14
For the above set of hyperparameters, report the best classification accuracy
a. 0.88
b. 0.86
c. 0.98
d. 0.68
Answer: b
Q7. Train an SVM classifier on the modified iris dataset. We recommend using sklearn. Use only the first two features for your model. We encourage you to explore the impact of varying different hyperparameters of the model. Specifically try different kernels and the associated hyperparameters. As part of the assignment train models with the following set of hyperparameters
RBF-kernel, gamma=0.5=0.5, one-vs-rest classifier, no-feature-normalization. Try C=0.01,1,10=0.01,1,10. For the above set of hyperparameters, report the best classification accuracy along with total number of support vectors on the test data.
a. 0.92, 69
b. 0.88, 40
c. 0.88, 69
d. 0.98, 41
Answer: c
<< Previous- Introduction to Machine Learning Week 3 Assignment Solutions
>> Next- Introduction to Machine Learning Week 5 Assignment Solutions
DISCLAIMER: Use these answers only for the reference purpose. Quizermania doesn't claim these answers to be 100% correct. So, make sure you submit your assignments on the basis of your knowledge.For discussion about any question, join the below comment section. And get the solution of your query. Also, try to share your thoughts about the topics covered in this particular quiz.
Checkout for more NPTEL Courses: Click Here!