
This set of MCQ(multiple choice questions) focuses on the Deep Learning NPTEL Week 5 answers.
Course layout
Answers COMING SOON! Kindly Wait!
Week 1: Assignment Answers
Week 2: Assignment Answers
Week 3: Assignment Answers
Week 4: Assignment Answers
Week 5: Assignment Answers
Week 6: Assignment Answers
Week 7: Assignment Answers
Week 8: Assignment Answers
Week 9: Assignment Answers
Week 10: Assignment Answers
Week 11: Assignment Answers
Week 12: Assignment Answers
NOTE: You can check your answer immediately by clicking show answer button. This set of “Deep Learning NPTEL Week 5 answers ” contains 10 questions.
Now, start attempting the quiz.
Deep Learning NPTEL Week 5 Answers
Q1. Look at the following figures. Can you identify which of the following options correctly identify the activation functions?
a) Figure 1: Sigmoid, Figure 2: Leaky ReLU, Figure 3: Tanh, Figure 4: ReLU
b) Figure 4: Sigmoid, Figure 3: Leaky ReLU, Figure 2: Tanh, Figure 1: ReLU
c) Figure 2: Sigmoid, Figure 3: Leaky ReLU, Figure 4: Tanh, Figure 1: ReLU
d) Figure 3: Sigmoid, Figure 2: Leaky ReLU, Figure 1: Tanh, Figure 4: ReLU
Answer: a)
Q2. What is the output of sigmoid function for an input with dynamic range[0, ∞]?
a) [0, 1]
b) [-1, 1]
c) [0.5, 1]
d) [0.25, 1]
Answer: a)
Q3. Find the gradient component for the network shown below.
a) 2p̂ x x1
b) 2(p̂ – p) x x1
c) (p̂ – p) x x1
d) 2(1 – p) x x1
Answer: c)
Q4. Which of the following are potential benefits of using ReLU activation over sigmoid activation?
a) ReLU helps in creating dense (most of the neurons are active) representations
b) ReLU helps in creating sparse (most of the neurons are non-active) representations
c) ReLU helps in mitigating vanishing gradient effect
d) Both b) and c)
Answer: d)
Q5. Suppose a fully-connected neural network has a single hidden layer with 50 nodes. The input is represented by a 5D feature vector and we have a binary classification problem. Calculate the total number of parameters of the network. Consider there are NO bias nodes in the network.
a) 250
b) 120
c) 350
d) 300
Answer: a)
Q6. A 3-input neuron has weights 1.5, 0.5, 0.5. The transfer function is linear, with the constant of proportionality being equal to 2. The inputs are 6, 20, 4 respectively. The output will be:
a) 40
b) 42
c) 32
d) 12
Answer: a)
Q7. You want to build a 5-class neural network classifier, given a leaf image, you want to classify which of the 5 leaf breeds it belongs to. Which among the 4 options would be an appropriate loss function to use for this task?
a) Cross Entropy Loss
b) MSE Loss
c) SSIM Loss
d) None of the above
Answer: a)
Q8. Consider the below neural network. p̂ is the output after applying the non-linearlity function fNL(*) on y. The non-linearlity fNL(*) is given as a step function.
a) 1, 1
b) 0, 0
c) 1, 0
d) 0, 1
Answer: c)
Q9. Consider the below neural network. p̂ is the output after applying the non-linearlity function fNL(*) on y. The non-linearlity fNL(*) is given as a step function.
a) 1, 1
b) 0, 0
c) 1, 0
d) 0, 1
Answer: c)
Q10. Suppose a nueral network has 3 input 3 nodes, x, y, z. There are 2 neurons, Q and F. Q – x + y and F = Q * z. What is the gradient of F with respect to x, y and z? Assume, (x, y, z) = (-2, 5, -4).
a) (-4, 3, -3)
b) (-4, -4, 3)
c) (4, 4, -3)
d) (3, 3, 4)
Answer: d)
Deep Learning NPTEL Week 5 Answers
Q1. The activation function which is not analytically differentiable for all real values of the given input is
a) Sigmoid
b) Tanh
c) ReLU
d) Both a & b
Answer: c)
Q2. What is the main benefit of stacking multiple layers of neuron with non-linear activation functions over a single layer perceptron?
a) Reduces complexity of the network
b) Reduce inference time during testing
c) Allows to create non-linear decision boundaries
d) All of the above
Answer: c)
Q3.
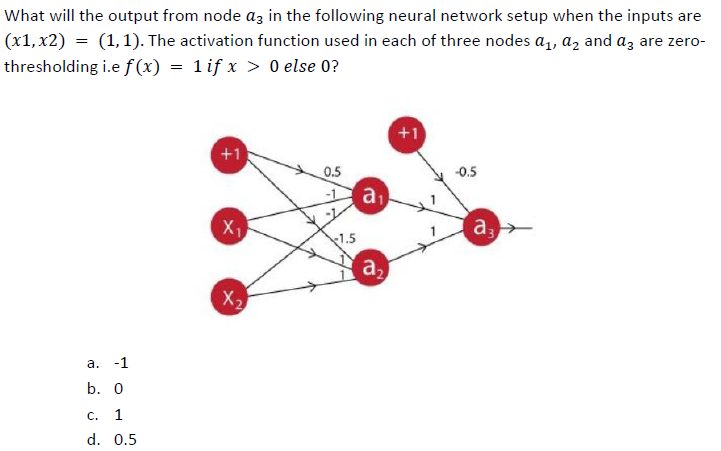
Answer:
Q4. Suppose a neural network has 3 input 3 nodes, x, y, z. There are 2 neurons, Q and F. Q = 4x + y and F = Q * z2. What is the gradient of F with respect to x, y and z? Assume, (x, y, z) = (-2, 5, -4).
a) (64, 16, 24)
b) (-24, -4, 16)
c) (4, 4, -13)
d) (13, 13, 24)
Answer: a)
Q5. Which of the following properties, if present in an activation function CANNOT be used in a neural network?
a) The function is periodic
b) The function is monotonic
c) The function is unbounded
d) Both a and b
Answer: a)
Q6. For a binary classification setting, what if the probability of belonging to class=+1 is 0.67, what is the probability of belonging to class =-1?
a) 0
b) 0.33
c) 0.67 * 0.33
d) 1 – (0.67 * 0.67)
Answer: b)
Q7. Suppose a fully-connected neural network has a single hidden layer with 10 nodes. The input is represented by a 5D feature vector and the number of classes is 3. Calculate the number of parameters of the network. Consider there are NO bias nodes in the network?
a) 80
b) 75
c) 78
d) 120
Answer: c)
Q8. For a 2-class classification problem, what is the minimum number of nodes required for the output layer of a multi-layered neural network?
a) 2
b) 1
c) 3
d) None of the above
Answer: b)
Q9. Suppose the input layer of a fully-connected neural network has 4 nodes. The value of a node in the first hidden layer before applying sigmoid nonlinearity is V. Now, each of the input layer’s nodes are scaled up by 8 times. What will be the value of that neuron with the updated input layer?
a) 8V
b) 4V
c) 32V
d) Remain same since scaling of input layers does not affect the hidden layers
Answer: c)
Q10. Which of the following are potential benefits of using ReLU activation over sigmoid activation?
a) ReLU helps in creating dense (most of the neurons are active) representations
b) ReLU helps in creating sparse (most of the neurons are non-active) representations
c) ReLU helps in mitigating vanishing gradient effect
d) Both b) and c)
Answer: d)
Deep Learning NPTEL Week 5 answers
Q1. Suppose a fully-connected neural network has a single hidden layer with 30 nodes. The input is represented by a 3D feature vector and we have a binary classification problem. Calculate the number of parameters of the network. Consider there are NO bias nodes in the network.
a) 100
b) 120
c) 140
d) 125
Answer: b) 120
Q2. For a binary classification setting, if the probability of belonging to class=+1 is 0.22, what is the probability of belonging to class=-1?
a) 0
b) 0.22
c) 0.78
d) -0.22
Answer: c) 0.78
Q3. Input to SoftMax activation function is[2,4,6]. What will be the output?
a) [0.11, 0.78, 0.11]
b) [0.0016, 0.117, 0.867]
c) [0.045, 0.9100, 0.045]
d) [0.21, 0.58, 0.21]
Answer: b) [0.0016, 0.117, 0.867]
Q4. A 3-input neuron has weights 1, 0.5, 2. The transfer function is linear, with the constant of proportionality being equal to 2. The inputs are 2, 20, 4 respectively. The output will be:
a) 40
b) 20
c) 80
d) 10
Answer: a) 40
Q5. Which one of the following activation functions is NOT analytically differentiable for all real values of the given input?
a) Sigmoid
b) Tanh
c) ReLU
d) None of the above
Answer: c) ReLU
Q6.
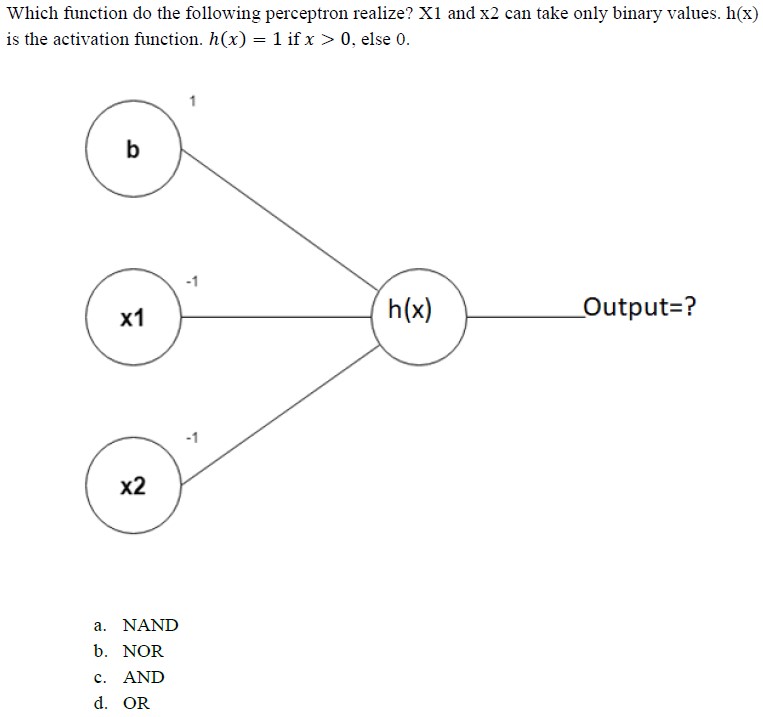
Answer: b) NOR
Q7. In a simple MLP model with 10 neurons in the input layer, 100 neurons in the hidden layer and 1 neuron in the output layer. What is the size of the weight matrices between hidden output layer and input hidden layer?
a) [10×1], [100 X 2]
b) [100×1], [10 X 1]
c) [100 x 10], [10 x 1]
d) [100x 1], [10 x 100]
Answer: d) [100x 1], [10 x 100]
Q8. Consider a fully connected neural network with input, one hidden layer, and output layer with 40, 2, 1 nodes respectively in each layer. What is the total number of learnable parameters (no biases)?
a) 2
b) 82
c) 80
d) 40
Answer: b) 82
Q9. You want to build a 10-class neural network classifier, given a cat image, you want to classify which of the 10 cat breeds it belongs to. Which among the 4 options would be an appropriate loss function to use for this task?
a) Cross Entropy Loss
b) MSE Loss
c) SSIM Loss
d) None of the above
Answer: a) Cross Entropy Loss
Q10. You’d like to train a fully-connected neural network with 5 hidden layers, each with 10 hidden units. The input is 20-dimensional and the output is a scalar. What is the total number of trainable parameters in your network? There is no bias.
a) (20+1)*10 + (10+1)*10*4 + (10+1)*1
b) (20)*10 + (10)*10*4 + (10)*1
c) (20)*10 + (10)*10*5 + (10)*1
d) (20+1)*10 + (10+1)*10*5 + (10+1)*1
Answer: b) (20)*10 + (10)*10*4 + (10)*1
<< Prev: Deep Learning NPTEL Week 4 Answers
>> Next: Deep Learning NPTEL Week 6 Answers
Disclaimer: Quizermaina doesn’t claim these answers to be 100% correct. Use these answers just for your reference. Always submit your assignment as per the best of your knowledge.
For discussion about any question, join the below comment section. And get the solution of your query. Also, try to share your thoughts about the topics covered in this particular quiz.