
This set of MCQ(multiple choice questions) focuses on the Deep Learning NPTEL Week 4 answers
Course layout
Answers COMING SOON! Kindly Wait!
Week 1: Assignment Answers
Week 2: Assignment Answers
Week 3: Assignment Answers
Week 4: Assignment Answers
Week 5: Assignment Answers
Week 6: Assignment Answers
Week 7: Assignment Answers
Week 8: Assignment Answers
Week 9: Assignment Answers
Week 10: Assignment Answers
Week 11: Assignment Answers
Week 12: Assignment Answers
NOTE: You can check your answer immediately by clicking show answer button. This set of “Deep Learning NPTEL Week 4 answers ” contains 10 questions.
Now, start attempting the quiz.
Deep Learning NPTEL 2023 Week 4 Quiz Solutions
Q1. Which of the following cannot be realized with single layer perception (only input and output layer)?
a) AND
b) OR
c) NAND
d) XOR
Answer: d) XOR
Q2. For a function f(θ0, θ1), if θ0 and θ1 are initialized at a local minimum, then what should be the values of θ0 and θ1 after a single iteration of gradient descent:
a) θ0 and θ1 will update as per gradient descent rule
b) θ0 and θ1 will remain same
c) Depends on the values of θ0 and θ1
d) Depends onf the learning rate
Answer: b)
Q3. Choose the correct option:
i) Inability of a model to obtain sufficiently low training error is termed as overfitting
ii) Inability of a model to reduce large margin between training and testing error is termed as Overfitting
iii) Inability of a model to obtain sufficiently low training error is termed as Underfitting
iv) Inability of a model to reduce large margin between training and testing error is termed as Underfitting
a) Only option (i) is correct
b) Both options (ii) and (iii) are correct
c) Both options (ii) and (iv) are correct
d) Only option (iv) is correct
Answer: c)
Q4. Suupose for a cost function J(θ) = 0.25θ2 as shown in graph below, refer to this graph and choose the correct option regarding the Statements given below θ is plotted along horizontal axis.
a) Only Statement i is true
b) Only Statement ii is true
c) Both statement i and ii are true
d) None of them are true
Answer: a)
Q5. Choose the correct option. Gradient of a continuous and differentiable function is:
i) is zero at a minimum
ii) is non-zero at a maximum
iii) is zero at a saddle point
iv) magnitude decreases as you get closer to the minimum
a) Only option (i) is correct
b) Options (i), (iii) and (iv) are correct
c) Options (i) and (iv) are correct
d) Only option (iii) is correct
Answer: b)
Q6. Input to SoftMax activation function is [3,1,2]. What will be the output?
a) [0.58, 0.11, 0.31]
b) [0.43, 0.24, 0.33]
c) [0.60, 0.10, 0.30]
d) [0.67, 0.09, 0.24]
Answer: a)
Q7. If SoftMax if xf is denoted as σ(xi) where xi is the jth element of the n-dimensional vector x i.e., X = [xi,…,xj,…,xn], then derivate of σ(xi) w.r.t. xi i.e., ƍσ(xi)/ƍxi is given by,
Answer: d)
Q8. Which of the following options is true?
a) In Stochastic Gradient Descent, a small batch of sample is selected rawndomly instead of the whole data set for each iteration. Too large update of weight values leading to faster convergence.
b) In Stochastic Gradient Descent, the whole data set is processed together for update in each iteration.
c) Stochastic Gradient Descent considers only one sample for updates and has noiser updates.
d) Stochastic Gradient Descent is a non-iterative process
Answer: a)
Q9. What are the steps for using a gradient descent algorithm?
1. Calculate error between teh actual value and the predicted value
2. Re-iterate until you find best weights of network
3. Pass an input through the network and get values from output layer
4. Initialize random weight and bias
5. Go to each neurons which contributes to the error and change its respective values to reduce the error
a) 1, 2, 3, 4, 5
b) 5, 4, 3, 2, 1
c) 3, 2, 1, 5, 4
d) 4, 3, 1, 5, 2
Answer: a)
Q10. J(θ) = 2θ2 – 2θ + 2 is a given cost function? Find the correct weight update rule for gradient descent optimixation at step t+1? Consider α=0.01 to be the learning rate
a) θt+1 = θt – 0.01(2θ – 1)
b) θt+1 = θt + 0.01(2θ – 1)
c) θt+1 = θt – (2θ – 1)
d) θt+1 = θt – 0.02(2θ – 1)
Answer: a)
Deep Learning NPTEL 2023 Week 4 answers
Q1.
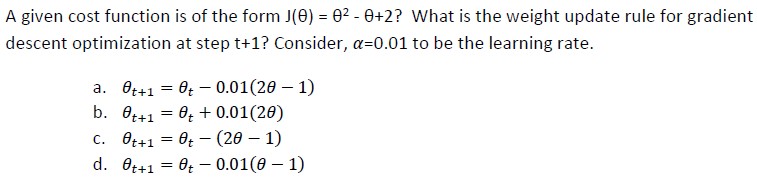
Answer: a)
Q2. Which of the following activation function leads to sparse acitvation maps?
a) Sigmoid
b) Tanh
c) Linear
d) ReLU
Answer: d)
Q3.

Answer: a)
Q4. Which logic function cannot be performed using a single-layered Neural Network?
a) AND
b) OR
c) XOR
d) All
Answer: c)
Q5. Which of the following options closely relate to the following graph? Green cross are the samples of Classs-A while mustard rings are samples of Class-B and the red line is the separating line between the two class.
a) High Bias
b) Zero Bias
c) Zero Bias and High Variance
d) Zero Bians and Zero Variance
Answer: c)
Q6. Which of the following statement is true?
a) L2 regularization lead to sparse activation maps
b) L1 regularization lead to sparse activation maps
c) Some of the weights are squashed to zero in L2 regularization
d) L2 regularization is also known as Lasso
Answer: c)
Q7. Which among the following options give the range for a tanh function?
a) -1 to 1
b) -1 to 0
c) 0 to 1
d) 0 to infinity
Answer: a)
Q8.
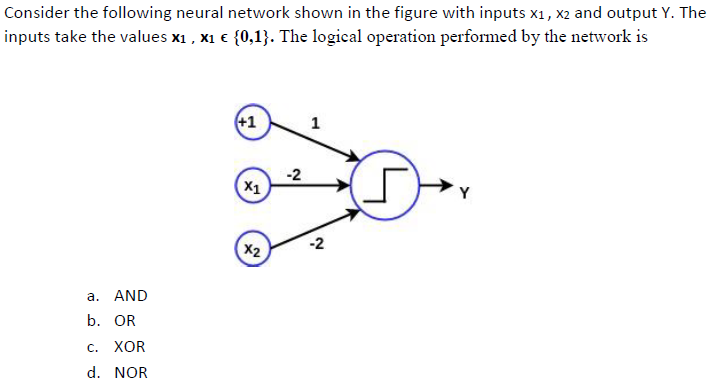
Answer: d)
Q9. When is gradient descent algorithm certain to find a global minima?
a) For convex cost plot
b) For concave cost plot
c) For union of 2 convex cost plot
d) For union of 2 concave cost plot
Answer: a)
Q10. Let X=[-1, 0, 3, 5] be the input of ith layer of a neural network. On this, we want to apply softmax function. What should be the output of it?
a) [0.368, 1, 20.09, 148,41]
b) [0.002, 0.006, 0.118, 0.874]
c) [0.3, 0.05, 0.6, 0.05]
d) [0.04, 0, 0.06, 0.9]
Answer: c)
<< Prev: Deep Learning NPTEL Week 3 Answers
>> Next: Deep Learning NPTEL Week 5 Answers
For discussion about any question, join the below comment section. And get the solution of your query. Also, try to share your thoughts about the topics covered in this particular quiz.
Is Q. no. 5 & 6 are correct?